1. 执行计划
执行计划 是优化器为读取请求的数据而选择的路线图,是优化器选择的访问计划和连接计划的组合。
一个最优的执行计划应该:
-
减少页的读取数量
-
消除不必要的排序,即通过按要求的顺序读取数据来消除因为 ORDER BY 和 GROUP BY 子句而产生的排序操作。
1.1 访问计划
动态服务器可以从多种方法中选择读取数据的方法。被选中的读取数据的方法称为访问计划(access plan)。 动态服务器可以使用以下访问计划:
-
顺序扫描 - 数据库服务器按物理顺序读取表中所有行。
-
索引扫描 - 数据库服务器读取索引页,尽可能应用筛选器并使用存于索引中的 ROWID 值检索满足条件的行。
-
Key-only索引扫描 - 当满足查询所需的数据全部包含在索引中时,数据库服务器将直接从索引中检索请求的数据,避免了从相关数据页中读取数据。
-
Key-first索引扫描 - 除了上界和下界筛选器,key-first 索引还使用了索引-键筛选器来减少一次查询需要读取的行数。
-
自动索引扫描 - 自动索引扫描 功能允许数据库服务器自动在一个或多个列上建立临时索引作为查询筛选器。数据库服务器读取这一临时索引来定位需要的数据。索引仅在查询过程中可访问。动态服务器的自动索引功能对某些 OLTP 批处理活动可能非常有用。它允许查询从索引中获益,而又不需考虑由于插入、更新和删除操作导致的索引维护开销。在活跃的 OLTP 环境中,由于频繁对表进行行的插入、更新或删除操作,由此带来的修改索引的开销将会非常明显。
1.2 连接计划
动态服务器可以选择的用于连接表的两个策略是:
-
Nested-loop嵌套循环连接
在Nested-loop连接 中,第一个表中的行被读取,连接列中的值将用于选择第二个表中对应的行。
如果第二个表上创建了索引,则可以使用索引查询。
-
Hash join哈希连接
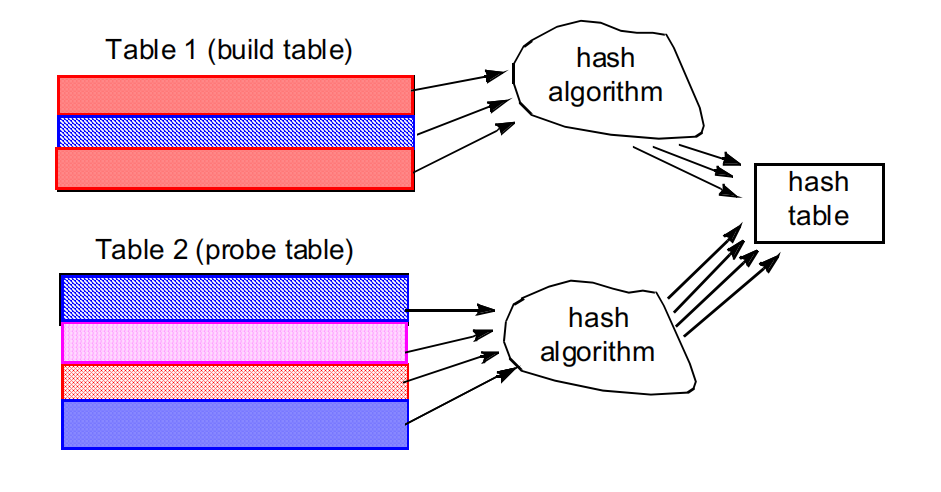
在哈希连接 的第一张表(build table )中,所有的行都被一个哈希算法处理,经过哈希 操作处理过的行随后被存于一个哈希表中。
第二张表(probe table )随后被顺序读取,其中的每行都将被其可能的哈希位置检查,以判定是否与 build table 中的某行匹配。
这种方式对于表的大小差别较大时最合适。为获得最佳性能,较小的表应该作为 build table,因为哈希表可能要被存放在内存中。
2. 优化器处理过程
2.1 优化器评定每个表的信息
① 检查每个筛选器的选择性
② 确定已有索引是否可用于:
- 筛选器
- ORDER BY 或 GROUP BY 子句
③寻找扫描表的最佳方法
- 顺序扫描
- 使用索引
由于查询代价很大程度上由表中必须读取的行的数量决定,在构建查询计划时,优化器首先考虑 WHERE 子句中的条件表达式以确定满足条件的行数量。这些条件表达式通常被称为筛选器 。
每个筛选器都会被检查以确定选择性(selectivity)。选择性 是一个介于0 和 1 之间的数,用来表明优化器估计的需要读取的行的比例。如果所有行都满足筛选器,选择性为 1。一个选择性很强的筛选器,其选择性接近于 0 。为确定筛选器的选择性,优化器会分析列数据的分布。如果无法获得该分布,优化器必须使用一个函数来计算预期的选择性。
下一步,优化器将确定现有索引是否可用于帮助检索基于筛选器条件, ORDER BY 或 GROUP BY 子句的查询。
最后,优化器确定将以顺序方式还是索引方式扫描数据表。
2.2 确定执行计划
①优化器首先通过自下而上、广度优先的搜索建立所有的连接对。
②然后,优化器:
— 通过评估以下内容考虑与访问路径和连接对相关的 I/O 和 CPU 代价:
- 表信息
- 索引信息
- 数据分布,如果可用
— 消除任意两个等价的连接对中代价更高的那个
— 在剩下的连接中选择代价最低的那个
为了确定查询计划,优化器需要为每个表考虑所有可能的访问路径,以及每个表对的可能连接方法。下一步,优化器可能会去掉任意两个等价的连接对中代价更高的那个。例如,表连接 (A x B )和 (B x A ) 等价,如果任意一张表的列上都没有 ORDER BY 或 GROUP BY 条件。
如果查询需要连接三个或更多的表,该过程将继续。一次连接的代价只需考虑剩余的连接对。等价的路径将被去掉。
最后,优化器选择剩余的具有最小预估代价的连接顺序。
3. 查看查询计划
通过启用 SET EXPLAIN 功能来获取优化器选择的查询计划和连接计划信息。
SET EXPLAIN ON;
SELECT …;
UPDATE …
SELECT …
INSERT …
DELETE …
SET EXPLAIN OFF;
在 SET EXPLAIN ON被进程或用户执行后,数据库服务器会生产一个文本文件,其中包含:
- 查询计划的预估代价
- 表被访问的顺序
- 是否需要临时表来处理查询。
- 每张表的访问方法。
- 每个连接对的连接方法
当优化器完成查询计划的写出后,服务器将使用该计划执行查询。
可以使用以下语句来生成一个查询计划,而又不用执行查询
SET EXPLAIN ON AVOID_EXECUTE;
在UNIX/Linux 系统中, sqexplain.out 文件将被创建在当前工作目录下:
${PWD}/sqexplain.out
Windows环境下,SET EXPLAIN ON 命令的输出将被写入
%DSDIR%\sqexpln\username.out
可以使用以下命令将执行计划输出到指定文件/tmp/explain.out中:**
set explain file to ‘/tmp/explain.out’;
3.1 临时文件的顺序扫描
QUERY:
SELECT * FROM stock ORDER BY description;Estimated cost:20
Estimated # of Rows Returned 74
Temporary Files Required For Order by
- client.stock:SEQUENTIAL SCAN
即使是最简单的查询也要经过优化以找到最佳的访问策略。
- 预估代价 - Estimated cost
每个查询预估代价都包含在查询报告中。在以上示例中,预估代价是 20。其位仅在与其他可能的路径进行比较时相关。预估代价不反映查询需要消耗的时间多少或资源大小。
- 预估返回的行数 - Estimated # of Rows Returned
优化器也会向 sqexplain.out 文件写入估计将返回的行数。这只是一种估计,但是通常很接近实际返回的行数量。在所有筛选器和连接条件都与索引相关,并且对查询中涉及表的统计数据是最新时,这一估计将最准确。
- 临时文件 - Temporary Files
当要为查询创建临时表或文件时,临时文件或表的创建原因将列于 sqexplain.out 文件中。在这个例子中,我们看见为处理 ORDER BY 子句需要进行排序。排序需要空间存储中间文件。如果可以使用索引来对元组排序,就不会有临时文件被创建。
- 表访问策略 - Table Access Strategy
最后,查询中每张表的访问策略会显示在报告里。在以上例子中,表将以SEQUENTIAL SCAN 的方式被访问,这意味着系统会从头到尾读取整张表。
3.2 使用筛选器的顺序扫描
QUERY:
SELECT * FROM stock WHERE unit_price > 20;Estimated cost:5
Estimated # of Rows Returned:251)client.stock:SEQUENTIAL SCAN
Filters : client.stock.unit_price > 20;
当查询包含 WHERE 子句时,该子句中的表达式可以指定连接条件或筛选条件。
- 筛选器Filter
筛选条件是一个表达式,该表达式用于筛选满足条件的行。当优化器选择使用 SEQUENTIAL SCAN 命令访问表并且筛选条件位于该表的列上时,该筛选条件将在Filters 部分列出。
存在这样的条件,它们在数据行从数据库读取之后 返回给用户程序之前 被添加到行上。表中所有的行将在SEQUENTIAL SCAN 期间被读取。然而,在任意一行被返回给用户程序之前,筛选条件stock.unit_price > 20 被应用到行上。如果符合条件,行将被返回给用户。如果不符合条件,行将不会在任何后续处理中被考虑。
3.3 Key-Only索引扫描
QUERY:
SELECT max(order_num) FROM orders;Estimated cost:1
Estimated # Rows Returned:11)client.orders: INDEX PATH
(1)Index Keys: order_num (Key-Only)
(Aggregate)
当查询可以利用一张或多张表上的索引时,优化器将选择使用这些索引中的一个或多个从表中检索数据行。
- 索引路径 - INDEX PATH
这类访问被称为 INDEX PATH。一般而言,INDEX PATH 是最快的访问方式。数据库服务器只需查看满足一个或多个筛选条件的行。读取的行越少,查询速度越快。
当优化器选择使用索引来访问一张表时,它会将每个索引使用的键写入至 sqexplain.out 文件中。这一信息被描述为表的索引键(Index Keys) 。
- Key-Only选择
在某些情况下,您想从表中检索的所有数据都包含在索引中。在这种情况下,无需读取数据页。此时,动态服务器将执行key-only 索引扫描。Key-only scan 允许数据库服务器只读取索引页。Key-only扫描消除了对数据页的不必要读取导致的 I/O 和 CPU 开销。
3.4 使用下界索引筛选器的索引扫描
QUERY:
SELECT * FROM stock, items
WHERE stock.stock_num = items.stock_num AND items.quantity > 1;Estimated cost: 14
Estimated # Rows Returned: 511 ) client.items: SEQUENTIAL SCAN
Filters: client.items.quantity > 12 ) client.stock: INDEX PATH
Index Keys: stock_num,manu_code
Lower Index Filter : (client.stock.stock_num= client.items.stock_num)
当查询访问多张表时,explain输出将按访问顺序列出所有的表。
- 索引读取的起点和终点
在执行表的索引检索时,通常以下两个条件之一定义这一索引检索:索引检索中决定起点的条件和决定终点的条件。
- 下界索引筛选器
为执行索引读取,优化器从定位第一个键值开始。一旦确定了这一位置,就可以按顺序读取索引,直到键值不再满足设定的条件集。定义索引初始位置的条件被称为下界索引筛选器 (lower index filter) 。如果合适,explain输出将包括每个索引使用的下界索引筛选器。
在上述示例中,stock.stock_num = items.stock_num 条件被用作stock 表上启动索引检索的条件。对于检索到的每个 items.stock_num 值,通过在嵌套循环连接中把该值用作键值,在stock 表上执行索引检索。
3.5 索引扫描:下界和上界索引筛选器
Query:
SELECT * FROM customer
WHERE customer_num BETWEEN 104 AND 111;Estimated: 2
Estimated # Row Returned:71)client.customer INDEX PATH
(1)Index Keys: customer_num
Lower Index Filter:
(client.customer.customer_num >= 104)
Upper Index Filter :
(client.customer.customer_num <= 111)
在某些情况下,检索启动于最开头,也就是从索引最开始的位置启动,这一点被称为起点 (start point) 。随后一直检索索引,直到某个特定的点,被称为终点 (stop point) 。
- 上界索引筛选器
当索引有与之相关的终点时, SET EXPLAIN 的输出将该条件展示为一个上界索引筛选器 (upper index filter) 。
对于索引的读取,一些查询既有下界索引筛选器又有上界索引筛选器。在这种情况下,一个条件定义从何处启动索引检索,另一个条件定义从何处中止检索。
3.6 动态哈希连接
Query:
SELECT * FROM items, stock
WHERE items.total_price = stock.unit_price;Estimated cost:11
Estimated # Rows Returned:751)DS.items:SEQUENTIAL SCAN
2)DS.stock:SEQUENTIAL SCANDYNAMIC HASH JOIN (Build Outer)
Dynamic Hash Filters: informix.items.total_price = informix.stock.unit_price
DYNAMIC HASH JOIN 关键字表明会在一张表上构建哈希表并且执行哈希连接。它包括用于连接的筛选器。缺省情况下,哈希表会建立在 SET EXPLAIN 输出列出的第二张表上。如果输出中包含了术语*(Build Outer)* ,则会在列出的第一张表上构建哈希表。
在上述示例中,将在items 表的total_price 列上构建哈希表。
3.7 哈希连接:并行扫描及排序线程
Query:
SELECT sales_cd, prod_cd, manufact, company
FROM product, sales
WHERE sales_cd IN (’new’)
AND product.prod_cd = sales.prod_cd
GROUP BY 2,3,1;Estimated cost:1088601
Estimated # Rows Returned:71)DS.product:SEQUENTIAL SCAN (Parallel, fragments:ALL)
2)DS.sales:SEQUENTIAL SCAN
filters: DS.sales.sales_cd IN (’new’)DYNAMIC HASH JOIN
Dynamic Hash Filters: DS.product.prod_cd = DS.sales.prod_cd
# of Secondary Threads:12
- 动态哈希连接
在 DSS 环境中,需要读取大量数据并且要求进行全表扫描,此时,优化器不再假设索引查询比按顺序的表扫描更好。相比其他连接方式,哈希连接(hash join)可以提供显著的性能优势,尤其是在连接表很大的情况下。DYNAMIC HASH JOIN 关键字表明将使用哈希连接。示例中的输出展示了连接中使用的表和筛选器。
- 顺序扫描(并行、分片:全部)
SET EXPLAIN 的输出将表明是否对分片表进行并行的顺序扫描,以及哪些分片会被读取。并行读取表分片可以极大提升查询性能。
3.8 Key-First 索引扫描
QUERY:
SELECT * FROM customer WHERE (customer_num > 120) AND ( (customer_num = 122) OR (customer_num = 123))Estimated Cost:1
Estimated # of Rows Returned:11)DS.customer:INDEX PATH
(1)Index Keys: customer_num (Key-First)
Lower Index Filter: DS.customer.customer_num > 120
Key-First Filters: ((DS.customer.customer_num =122 OR DS.customer.customer_num = 123 ) )
除了下界和上界筛选器,key-first 索引扫描还使用了其他的键筛选器,以减少查询读取的行数。
通过使用传统的索引扫描方式,优化器可能会使用下界索引筛选器 (customer_num > 120) ,然后读取所有索引键和对应的拥有大于 120 的 customer_num 值的数据页。数据库服务器只有在将数据读进内存之后才能筛选掉其它不符合条件的行(customer_num 不等于 122 或 123),然后再将数据发送给客户端。
通过使用key-first索引扫描,优化器会在访问数据页之前使用所有筛选条件(顾客大于 120 且 等于 122 或 123)。如果在 customer_num 列上构建了一个唯一索引,key-first索引扫描将消除 customer_num 值为 122 和 123 以外的所有索引条目,并保证最多只需读取两个数据页就能解决查询。
3.9 跳过重复的索引扫描
QUERY:
UPDATE customer SET cust_status = “C” WHERE EXISTS
(SELECT customer_num FROM orders WHERE customer.customer_num = orders.customer_num )Estimated Cost:10
Estimated # of Rows Returned:231)Administ.orders:INDEX PATH (Skip Duplicate)
(1)Index Keys: customer_num (Key-Only)
2)Administ.customer:INDEX PATH
(1)Index Keys: customer_num
Lower Index Filter:Administ.customer.customer_num = Administ.orders.customer_num
NESTED LOOP JOIN
跳过重复的索引扫描 (skip duplicate index scan) 能够防止对辅助表上的同一个值进行多次索引查询。以上示例中,对同一位顾客而言,可能存在多个 order 记录。这可能导致在 orders 表中重复检索相同的值以及重复更新相同的行。
跳过重复的索引扫描可以保证只返回唯一的customer_num值,避免了对同一行进行重复扫描和更新。
Key-only索引扫描和跳过重复的扫描结合可以显著减少 I/O。
3.10 索引自连接
QUERY:
SELECT * FROM tab1
WHERE col1 >= 1 AND col1 <= 10
AND col2 >= 100 AND col2 <= 200
AND col3 >= 1000 AND col3 <= 2000;Estimated Cost: 120
Estimated # of Rows Returned: 11)informix.t: INDEX PATH
(1) Index Keys: col1 col2 col3 (Key-Only) (Serial,
fragments: ALL)
Index Self Join Keys (col1 col2)
Lower bound: t.col1 >= 1 AND (t.col2 >= 100)
Upper bound: t.col1 <= 10 AND (t.col2 <= 200)
Lower Index Filter: (t.col1 = t.col1 AND t.col2 = t.col2)
AND t.col3 >= 1000
Upper Index Filter: t.col3 <= 2000
Index Key Filters: (t.col2 <= 200) AND (t.col2 >= 100)
在处理基于范围的索引扫描时,如果索引的前导列具有高度重复的值,将使用索引自联接,而不是通过扫描索引树。
扫描的第一部分获取前导列的唯一值,然后联接到内部扫描,利用前导列的唯一值的连接并过滤其余列。索引自连接消除了读取的很大一部分的索引树,更少的 I/O,能极大改善性能。
上述示例描述了一个查询,该查询将使用包含六列的索引,其中前两列具有高度重复的值。优化程序已决定对 col1 和 col2 进行自连接,然后将结果与 col3 连接。
3.11 优化子查询
使用子查询的 SQL 语句:
SELECT * FROM customer
WHERE customer_num IN (
SELECT customer_num FROM orders
WHERE order_date = TODAY);
相关的子查询:
SELECT * FROM customer c
WHERE exists (
SELECT customer_num FROM orders
WHERE orders.customer_num = c.customer_num
AND order_date = TODAY);
子查询 (subquery) 是一个 SELECT 语句,它被包含在 SELECT、 INSERT、UPDATE 或 DELETE 语句的 WHERE 子句中。
一种特殊类型的子查询称为相关 (correlated) 子查询。相关子查询是指从外部 SQL 语句接收值的子查询。对于每个被检索并由外部 SQL 语句传递的值,子查询或内部 SQL 语句都必须被执行一次。
大部分子查询也可被写为连接语句。
SELECT customer.* FROM customer, orders
WHERE customer.customer_num = orders.customer_num
AND orders.order_date = TODAY;
4. 查看当前SQL信息
$ onstat -g sql
Sinoregal SinoDB Dynamic Server Version 12.10.FC8 -- On-Line -- Up 43 days 23:39:56 -- 2757528 Kbytes
Sess SQL Current Iso Lock SQL ISAM F.E.
Id Stmt type Database Lvl Mode ERR ERR Vers Explain
327 sysadmin DR Wait 5 0 0 - Off
326 sysadmin DR Wait 5 0 0 - Off
325 sysadmin DR Wait 5 0 0 - Off
324 sysadmin CR Not Wait 0 0 - Off
$ onstat -g sql 327
Sinoregal SinoDB Dynamic Server Version 12.10.FC8 -- On-Line -- Up 43 days 23:40:04 -- 2757528 Kbytes
Sess SQL Current Iso Lock SQL ISAM F.E.
Id Stmt type Database Lvl Mode ERR ERR Vers Explain
327 sysadmin DR Wait 5 0 0 - Off
Last parsed SQL statement :
INSERT INTO ph_run ( run_id, run_task_id, run_task_seq, run_retcode,
run_duration, run_ztime, run_btime, run_mttime ) VALUES ( 0, ?, ?, ?, ?,
?, ?, ? )
onstat -g sql 命令包含每个会话执行的最后一条 SQL 语句的概览信息。onstat -g sql 包含的字段有:
| 列名 | 说明 |
|---|---|
| Session ID | 执行 SQL 语句的用户的会话 ID |
| Statement type | 诸如 SELECT、UPDATE、DELETE 和 INSERT 的语句类型 |
| Current database | 会话当前的数据库的名字 |
| Isolation level | 当前隔离级别 |
| Lock mode | 当前锁模式 |
| SQL ERR | 最后一个 SQL 错误 |
| ISAM ERR | 最后一个 ISAM 错误 |
| F.E.Vers | 客户端应用程序的 Sinoregal DS 版本 |
如果想查看更详细的sql信息,可以使用使用
onstat -g sql session_id
也可以通过执行以下命令,检索活动的 SQL 会话列表:
SELECT * FROM sysmaster:syssqlcurses;
或
SELECT * FROM sysmaster:syssqlcurses WHERE scs_session = <session_id> ;