本文接上一篇创建、更改、删除索引 - 知识库 / 运维管理 - Sinoregal Tech Forum继续讨论如何管理和维护SinoDB数据库的B+树索引。
1. 索引的好处
① 基于索引的排序
一列或多列的索引可用于按序取回数据。使用索引读取数据可以让数据库服务器按照请求的顺序直接返回数据,免去了排序的操作。
② 强制保证唯一性
当使用 UNIQUE 关键字为一列创建索引时,列中的每一行值都是唯一的。这样就不需要应用程序执行任何唯一性检查。
③ Key-Only选择
当 SELECT 子句列出的所有列都属于同一个索引时,动态服务器不必读取数据行,因为所有数据都可从索引中直接获取。
2. 索引的代价
① 磁盘空间开销
索引的代价首先是磁盘空间开销。为表创建索引会使表需要的磁盘空间增加若干页,甚至为索引分配与行数据一样大的磁盘空间也并不罕见。
② 处理时间代价
第二个代价是修改表时所需的处理时间。在插入、更新或删除表数据的时候,也需要维护表的索引。根据不同的操作类型,索引维护需要的时间也不一样。
- 删除开销
从表中删除一行时,会从所有索引中删除该行的索引键,数据页中该行数据会被清空。
- 插入开销
向表中插入一行时,所有索引都会插入相关条目。每个索引中跟该行相关的节点都会被查找并重写。
- 更新开销
当一行被更新时,会在每个索引中查找被修改列相关的条目。索引条目将被重写以删除旧条目;新的列值会被定位到同一个索引中,或者创建一个新的条目。
许多的插入和删除操作可能引起 B+ 树索引的大幅重构,这会导致更多的 I/O 操作。
3. B+树维护
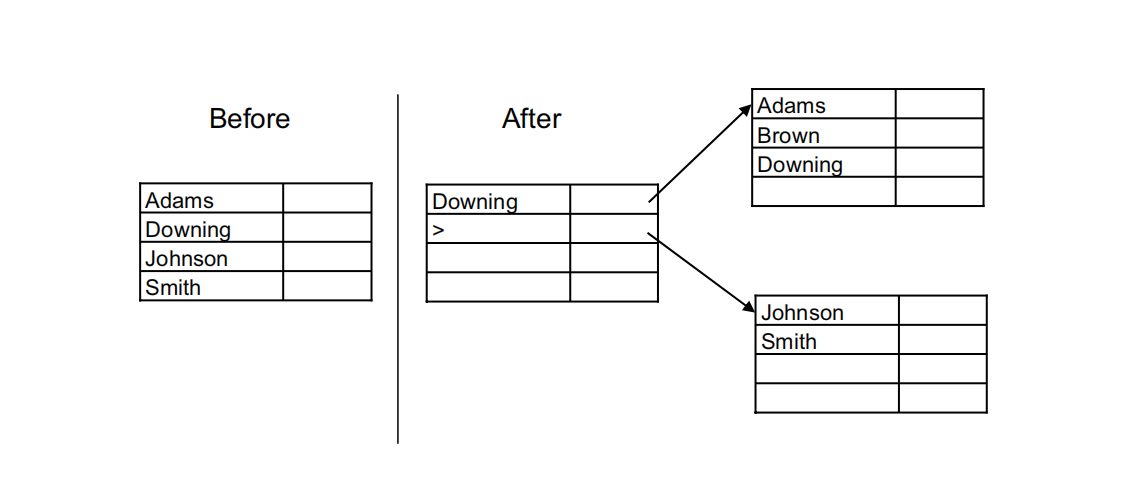
B+ 树索引的维护需要对节点进行分割、合并及打乱(shuffle),以维护一个高效的树并适应关键项的插入、更新和删除操作。
删除压缩
为了释放索引页面并维护一个压缩索树,动态服务器会在物理删除索引条目后评估每一个节点,以判断该节点是否是压缩候选节点。如果一个节点不是根节点且包含的索引项少于三个,该节点成为压缩候选节点。
合并
如果左边或右边的兄弟节点可以容纳候选压缩节点中剩余的索引键,索引项将被合并 到兄弟节点中,候选节点将被释放或重新利用。
打乱
如果所有兄弟节点都无法容纳索引项,动态服务器将尝试选择包含最多项目的兄弟节点,并将其中的某些项目移到候选压缩节点中,使得这两个节点包含相同或几乎相同数量的键,已达到平衡的目的。
打乱并重新分配有助于维护一个平衡的树,防止出现一个节点已满而临近节点却没有的情况。这反过来有助于降低分割节点的可能性。
分割
当新的键值必须被添加到一个已满的索引节点中时,必须将节点分割以提供足够的空间给新键。要执行节点分割,数据库服务器必须写入三个页面。
索引管理的目标
索引管理的目标是减少索引的分割、合并和打乱操作,因为:
-
需要额外的处理。受影响的索引页面会被锁定并由数据库服务器写入。
-
需要更多的磁盘空间。分割后,新页面未被放满。存储未满的节点会增加索引所需的磁盘空间。
-
大规模的分割会降低缓存的效率。如果一个全满的节点含有 200 个键值,分割后可能需要在内存中缓存 3 个页面来访问同样的 200 个键。
5. 索引创建指南
① 在以下位置创建索引:
-
连接列
-
选择性筛选列
-
常用于排序的列
② 避免高度重复的索引
③ 对于主要用来存储数据的表,限制索引个数
④ 保持索引键值短小
⑤ 使用复合索引以提高唯一性
⑥ 使用聚集索引加速检索速度
⑦ 在大规模更新、删除或插入操作之前禁用索引功能
索引连接列
任何连接表达式涉及的列中至少有一个应该包含索引。如果没有索引,数据库将执行以下操作:
- 在连接前创建一个临时索引,并使用排序归并连接或嵌套循环(nested loop)联接
- 使用哈希联接(hash join)来顺序扫描该表。
当连接表达式的两列均有索引时,优化器在构建查询计划时将有更多选择。作为 OLTP 环境下的通用准则,对连接表达式中的常用列应该添加索引。系统会自动对主键和外键进行索引。如果只对连接中的一张表进行索引,请对包含唯一连接列键值的那张表来构建索引。唯一索引(unique index)比重复索引(duplicate index)更适合进行联接操作。
在执行大规模数据读取和顺序扫描表的决策支持环境(DSS) 中,索引未必是实现联接的最好方式,哈希联接(hash join)可能是更好的选择。
索引筛选列
如果某列常被用来筛选某一大型表的行,请考虑对该列建立索引。优化器可以使用该索引来挑选需要的行,避免顺序扫描整张表。
该列不包含太多重复值的情况下,才会节省时间。相比于顺序访问,利用索引的非顺序扫描需要更多的 I/O 操作来取回更多的行,所以如果一个筛选表达式使得该表的大部分被返回,数据库服务器可能仍然会按顺序读取该表。
排序相关的索引列
当对一张大表进行的选择包括 ORDER BY 或 GROUP BY 子句时,数据库服务器必须将行按顺序排列。如果在排序的列上有索引,优化器可以通过索引按顺序读取行,从而可以在查询时消除排序。
避免高度重复索引
避免索引含有许多重复值的列。比如‘性别’列。
当这种索引被用于查询时,性能也会降低,因为通过一个键值指引的行可能散布在整个磁盘。当数据库服务器尝试通过索引来访问每一行时,它必须为读取的每行执行一个 I/O 操作。如果对一个高度重复的列进行索引是必要的,考虑将其与具有较少重复值的另一列组成一个复合键。
不稳定表
避免在不稳定表上建太多索引。因为更新索引时必须进行额外的读取,所以当一个频繁更新的表上具有太多索引时会导致一些性能降低。
保持键值短小
键值应该很短小。键值越小,就可以在 B + 树的节点中存储更多的值。键值越大,能在 B + 树的节点中存放键数量就越少。更多的节点需要更多的 I/O 操作来访问被索引的行。
一个例外是 key-only 选择。如果查询的所有列都在索引中,就不必从表中读取数据,从而提高了这种索引的效率。
复合索引
使用复合索引可以提高唯一性。
如果一个表的若干列与另一个表的若干列进行连接,则在具有较大行数的表的列上创建一个复合索引。
如果在查询中多个列上有经常使用的筛选条件,则在查询使用的筛选列上创建复合索引。
使用复合索引来加快对一个包含许多重复值的索引列的 INSERT 速率。为包含许多重复值的列添加一个唯一(或相对的) 列以增加键的唯一性,并减少重复列表的长度。
当表经常按某几列进行排序时,这些列上的复合索引可以帮助避免反复排序。
聚集索引
聚集(Clustering)索引适用于相对静态的表。创建聚集索引需要大量的时间和空间。通过将数据按照所需的顺序加载到表中,就可以避免聚集操作,这时候行的物理顺序就是它们插入的顺序。
删除或禁用索引
当需要插入或更新表中大部分行时,请考虑禁用或删除索引。
- 第一步:禁用索引
set indexes for tablename disabled;
-
第二步:加载或更新行
-
第三步:启用索引
set indexes for tablename enabled;
这样做有两个积极影响:
-
首先,因为需要更新的索引更少,整个过程将运行地更快。通常,通过批处理获得的性能改善将抵消 DISABLE 或 DROP 命令执行后重建索引的时间。
-
其次,新创建的索引通常更紧凑、更有效。
禁用而不是删除索引的主要优势是条目无需被删除并重新输入进系统目录表中。
6. 并行索引建立
SinoDB 动态服务器实现了一个复杂的设计以支持快速索引建立。该设计将索引建立过程划分为三个 子任务(subtask) 。这一职能的划分被称为垂直并行方式(vertical parallelism) 。
首先,扫描线程从磁盘中读取数据。
下一步,数据将被传至分类线程中。
最后,通过 b-tree appender 线程,有序集合将被添加到单个索引树中。
如果 PDQ PRIORITY 被设定为 0,为一个分类分配的最大内存是 128 KB。这样可以防止动态服务器在索引建立过程产生大量的分类线程。如果 PDQ 被打开,(PDQPRIORITY > 0),性能优势将会变得很明显。
7. 内存常驻索引
set index state_ix memory_resident;
该功能允许特定索引的一个或多个片段在共享内存缓冲池中得到优先处理。当数据库服务器要求一个空缓存时,内存常驻对象所在的页将被最后考虑用作被替换的页。
如要查看内存常驻索引,请使用 onstat -P 或 onstat -t 命令。